(Link https://just-tit.com)
Hace tiempo que me surgió la idea. Estaba jugando con los bots para telegram, creando varios buscadores inline, cuando me asaltó la duda de si sería posible hacer una búsqueda sobre las principales páginas web de vídeos porno que existen actualmente. Investigando un poco encontré que existía una API para este fin.
Pornhub API
Las primeras versiones no funcionaban mal, la API parecía funcionar bien, y además ofrecen programa de afiliados, con lo cual podría generar ingresos por enviar tráfico a estas webs. Demasiado fácil. Estaba claro que tenía que fallar por algún sitio, y lo hizo. La API está limitada a unas pocas peticiones por minuto, con lo cual no podría tener un bot que aceptase peticiones de los usuarios sin quedarse tirado a cada poco. ¿Cuál es la solución a esto? Hold my beer, ya lo indexo yo.

Hold my beer
Una de las cosas que tenía claras desde el principio es que este proyecto debía de montarse sobre AWS. Esto me permitiría hacer algo a pequeña escala, sin gastarme demasiado dinero, pero con posibilidades de crecer en caso de que el proyecto empezase a generar visitas. También tenía claro que debía centrarme en la optimización de los servicios, dado el volumen de datos que me iba a tocar procesar.
Decidí usar wordpress como base, por similitud de estructura con los datos que recibía de la red de pornhub (título, contenido, categorias y tags), aún a sabiendas de que un wordpress con varios millones de posts iba a hacer aguas por algún lado. De esta forma, podría centrarme en la importación de los datos y ya me encargaría de tapar las fugas una vez realizado el proceso.
El proceso de importación resultó sencillo de programar, pero ligeramente complicado de optimizar para conseguir que finalizase dentro de un margen de tiempo razonable. Por una parte, tuve que desestimar la opción de usar el importador de posts de wordpress, debido a su lentitud (estamos hablando de casi 60 millones de lineas en la tabla de categorias/tags), programar por separado el generador de slugs (uno de los códigos de wordpress que mas me ha dolido ver), y aprovisionar un número correcto de IOPS en AWS (con cuidado de no gastar una fortuna).
En un primer intento, añadí la descarga de thumbnails de los vídeos al proceso, pero después de hacer un cálculo aproximado y saber que ocuparían unos 50Tb (unos $1200/mes para alojarlos en un S3 bucket), llegué a la conclusión de que el hotlinking sería mucho más sano para mi bolsillo.
Llegados a este punto, tenemos ante nosotros una instalación base de wordpress con 9 millones y pico de posts, organizados por tags y categorías, con sus url’s bonitas, y que simplemente no funciona. Un vistazo al log de slow queries de mysql me sacó de dudas, y empezó otra de las batallas que me ofreció este proyecto. En resumen : añadido de varios índices a las tablas de wordpress y retirada de elementos tales como el paginador o el link al siguiente/anterior post por por fecha, que generaban consultas de varios minutos sobre la bd.

Mysql Slow Queries
Una vez terminada la optimización de wordpress para que no haya consultas «lentas», llegaba la hora de enfrentarse al núcleo del problema, y lo que podría llegar a ser el punto fuerte del proyecto : las búsquedas. Estaba claro que no podrían hacerse contra la base de datos, así que habría que recurrir a un servidor de búsqueda. Sopesé Solr, Sphinx y ElasticSearch, decantándome por este último debido a estar implementado en AWS. El proceso para sincronizar toda esa cantidad de datos supuso algo similar al proceso de importación (aprovisionando IOPS necesarios sin arruinarme), y una vez finalizada, ya podía hacer que wordpress tirase búsquedas y navegación por tags y categorías contra el servidor ElasticSearch.
Infraestructura AWS
Ya sólo faltaba un template bonito y responsive (30€ del ala) y un nombre de dominio resultón (otros 10€).

Just-tit.com
Y el bot de telegram, por supuesto, consulta ahora a la API REST de mi propio wordpress, que no está limitada, y tiene a su alcance toda esta cantidad inimaginable de porno.
https://telegram.me/pornagentbot
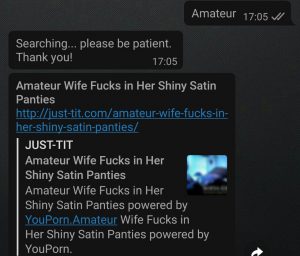
Telegram @pornagentbot